
DMBOKの要約本
以下、個人的に印象に残った部分をメモ
プランニング
- まず初めにデータアーキテクチャの設計をする必要がある
- 具体的には以下を洗い出して図式化する
- あるデータがどんなビジネスのどんな業務に貢献しているのか
- あるビジネス・業務がどんなデータに依存するのか
- ここが疎かになっているとデータを変更したり削除したら想定外の業務が回らなくなったなどのインシデントが起こりうる
実装・運用: システム
要件に合わせてデータストレージの選定、実装、保守管理を行う
- データ量の基準
- データが少ないならば、Spreadsheet、RDBMSやELKスタック(Elasticsearch + Logstash + Kibana)で充分な場合もある
- データが多くなることが想定される場合はDWH製品を利用する
- BigQuery、Snowflake、Redshift、Treasure Dataなど
- SoE(System of Engagement: 体験重視)かSoR(System of Record: 記録重視)かの基準
- DWHは気軽に大量のデータを処理できるため、探索的なデータ分析に向いている
- RDBMSの場合はスキーマ制約やトランザクション管理が優れている
- 初期のフェーズではDWHにラフにデータを入れ込んで探索的に分析を行い、業務に組み込めたらRDBMSにデータを移行してバッチやAPIなどで分析を行うやり方もある
データの統合を行う
- 事業が進んでくるとデータソースがどんどん増えてくる、そしてそれらのデータを統合して一元的に分析したくなる
- そこで必要なのがETL(Extract, Transform, Load)処理
- 異なるデータソースからデータを取得
- それらのフォーマットを揃える(ex. DateのTimezoneやFormat)、データへのアクセス制御
- 統合データの監視 (不整合や更新遅延、漏れがないか)
- スタートアップでのシンプルなパイプラインの例
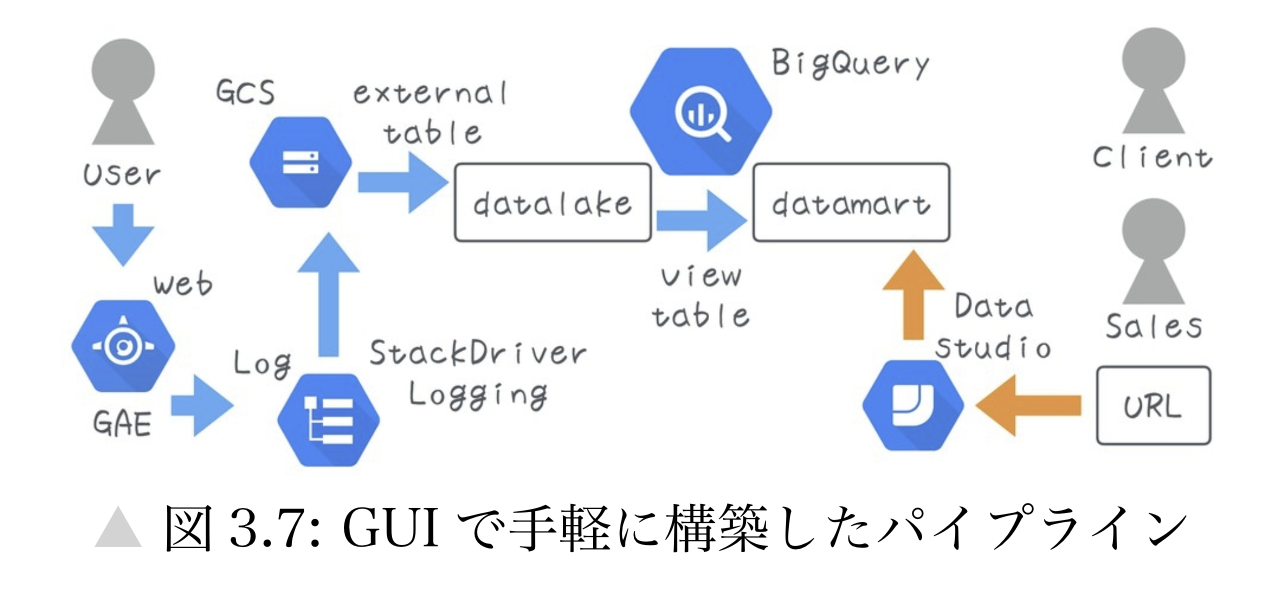
実装・運用: ロジック
データモデリング
- データ同士の関係性を図示すること
- データ同士の関係性を把握せずに様々なデータの整合性を保つことは不可能
- データの関係性を3つのレベルで書き出す
- 概念モデル
- 「何と何が紐づくか」というレベル
- 論理モデル
- 「具体的にどのようなデータを持って紐づくか」というレベル
- 物理モデル
- 具体的な実装の詳細
- RDBでいうER図のレベル
- 概念モデル
- 学校と学生を例にすると以下の通り
- 概念モデル
- 学校は学生を在籍させるので、学校一覧と学生一覧のデータは紐づく
- 論理モデル
- 学校一覧には学校コードと学校名が含まれる
- 学生一覧には学生番号と在籍している学校コード、学生指名が含まれる
- 学校一覧と学生一覧は学校コードを介して紐付いている
- 物理モデル
- SchoolsテーブルとStudentsテーブルのER図
- 概念モデル