
アーキテクチャ設計の進め方
1. 命名によって切り分けられた責務の境界を守る
何よりも重要なのは、責務を明確にイメージできる名前づけです。 「ViewController」という名前では、Fatになるのは半ば必然です。 同じように ~Manager、 ~Service、 ~Util といったクラス名も、責務がイメージできず肥大化や侵食に繋がるアンチパターンといえます。 あるいは、本来は明確な名前をつけられる複数のモジュールをひとつにまとめてしまっているサインと考えてもよいでしょう。 ある Util が Converter と Validator と Formatter と Sender を兼任していたら、それらは分けるべきである可能性が高いです。
これはモジュールに限ったことではありません。 メソッドや変数においても、責務をイメージできない名前をつけた途端に設計は腐敗への道を辿ります。
2. 設計の原則を守りながらリファクタリングでイテレーティブに設計する
アジャイル開発の提唱者の一人であり、書籍「アジャイルソフトウェア開発の奥義」の著者でもある Robert C. Martin 氏(以降、彼の愛称から Uncle Bob)は、アジャイル開発は次のようなサイクルであると述べています。
- アジャイルのプラクティスに従って問題を発見
- 設計の原則を適用して問題を分析
- 適切なパターンを適用して問題を解決
設計の原則という言葉が出てきました。
原則は、責務の分割単位が適切かどうかを検証するための物差しです。 SOLID原則、KISS、YAGNIなどが原則に当たります。
Uncle Bobは、原則はコードから臭いを取り除くものであると表現しています。 具体的なコードの臭いには次のようなものがあります。
• 硬さ: 変更しにくいシステム。1つの変更によってシステムの他の部分に影響が及び、多くの変更を余儀なくさせるようなソフトウェア
• もろさ: 1つの変更によって、その変更とは概念的に関連のない箇所まで壊れてしまうようなソフトウェア
• 移植性のなさ: 他のシステムでも再利用できる部分をモジュールとして切り離すことが困難なソフトウェア
• 扱いにくさ: 正しいことをするよりも、誤ったことをするほうが容易なソフトウェア
• 不必要な繰り返し: 同じような構造を繰り返し含み、抽象化してまとめらられる部分がまとまっていないソフトウェア
• 不必要な複雑さ: 本質的な意味を持たない構造を内包しているようなソフトウェア
• 不透明さ: 読みにくく、わかりにくい。その意図がうまく伝わってこないソフトウェア
本能的な違和感を言語化し、「原則に違反しているからまずい」と根拠をもって指摘し、最終的に高凝集・疎結合を実現するために設計の原則はあります。
適切な設計の判断のためには 変更可能性がどこにあるか知らなくてはならないということです。 ただそのような努力をしても、想定しない変更に行き当たることがしばしばあります。 考えていた計画が頓挫することもあります。開発はいつだって、想定どおりに進まないものです。
答えは、リファクタリングです。 一度設計したら終わりとするのではなく、設計を状況に応じて少しずつ進化させていくイテレーティブなものだととらえるのです。
リファクタリングについてはいくつかの典型的な誤解があります。 誤解のひとつは、リファクタリングは作り直しではないということです。何の保証もなくコードを書き替えるのは、リファクタリングではなくただの破壊です。 書き換えは、その前後で既存の機能が壊れていないことを確かめながら行わなければなりません。
そのためにはテストが必要であり、ひいては設計はテストのしやすさを前提に進める必要があります。 ちなみに最速のテストとは何かというと、型付けです。型システムの力を借りることで、処理結果が想定に収まることをテストコードを書くよりも早くコンパイラレベルで保証できるようになるケースが、多くあります。
3. イテレーティブな設計の中でパターンが見えてきたらパターンを適用する
あなたが覚えたアーキテクチャの"パターン"は、イテレーティブな設計のフェーズの中で、いつ使うことになるのでしょうか。
「アジャイルソフトウェア開発の奥義」には次のような記述があります。
リファクタリングをしながら、モジュール間の結びつきを弱めたり、シンプルにしたり、よりわかりやすく改善するその過程で、そのコードがある特定のデザインパターンに近づいていることに気がつくことがある。 その時点で初めて、デザインパターンの名前に対応するようにクラス名や変数名を変え、また、パターンをより定型的な形式で使えるようにコードの構造を変えるようにする。
これをUncle Bobはコードがデザインパターンに回帰していくと表現しています。 パターンが最初にあるのではなく、コードを修正していく過程で、その最終形にパターンを見出すのです。
スタートは単純な設計からです。もしそこで既知のパターンが適用できそうであれば、その結果どうなるかを想像できます。 パターンの利点・欠点は分析済みですので、いきなり完成度 の高い設計に辿り着くこともありえます。
あるいは少しずつテストを書きながらリファクタリングを進めることもありえるでしょう。 「コードの臭い」を感じたら、原則を使って原因を突き止めます。 小さな歩幅でリファクタリングを行ううちに、全体の構造がより洗練されます。 するとそこに新たなパターンの適用の余地が見えてくる。 パターンはショートカットのようなものになります。
SOLID原則を振り返る
S: 単一責任原則 (Single Responsibility Principle)
- クラス(型)を変更する理由は2つ以上存在してはならない
単一責任原則について勘違いしやすいのが、判断の基準になるのが変更の理由であるという点です。
凝集という観点から言い換えると、手続きや利用シーンが近い機能がひとつのモジュール内に凝集していることは開発のしやすさにつながりますが、再利用性は落ちます。 開発のしやすさと再利用性はトレードオフであり、そのバランスはプロジェクトの時期・要件によって流動するものです。 変更可能性のない責務を無意味に切り離すことは、逆に「不必要な複雑さ」に結びつくおそれがあります。 変更の理由は、変更の必要性が生じたときにはじめて「理由」となりえます。 単一責任原則 を適用すべきか判断するには、その点の検討を忘れてはなりません。
D: 依存関係逆転の原則 (Dependency Inversion Principle)
具体ではなく抽象に依存する
- 上位レベルのモジュールは下位レベルのモジュールに依存すべきではない。両方とも抽象に依存すべきである
- 抽象は詳細に依存してはならない。詳細が抽象に依存すべきである
なぜ依存関係の「逆転」なのか
依存関係逆転の原則という名前に「逆転」という単語が入っているのは、なぜでしょうか。
モジュールには、使われる側(上位)と使う側(下位)の関係があります。お互いが相手のことを知っている場合、それは 病理学的結合という最悪の結合だと見なされます。 上位モジュールは下位モジュールのことを気にしてはいけません。 下位モジュールの実装の変化によって上位モジュールの変更が強いられては、安定した設計とはいえないからです。
しかし上位モジュールから下位モジュールへの呼び出しが発生することはよくあります。 その場合、下位モジュールのインターフェイスを上位モジュールが知っていないといけません。 この矛盾は「上位モジュールが protocol を宣言する」「下位モジュールはその protocol に合わせて実装する」という関係を作れば解決できます。 そこで使われるのが依存関係逆転の原則というわけです。 上位モジュールが自分のために宣言した protocol でなければ、依存関係の「逆転」はできませんので、protocolの命名を「上位モジュールのProtocol」とする必要がある点に注意が必要です。
I: インターフェイス分離の原則 (Interface Segregation Principle)
- クライアントに、クライアントが利用しないメソッドへの依存を強制してはならない
- インターフェースは必要最小限まで分割するべきである
静的型付け言語は「できることだけをできるようにする」ことを目指す
O: 開放閉鎖の原則 (Open/Closed Principle)
- クラス(型)は拡張に対して開いていて、修正に対して閉じていなければならない
字面を見てもよくわからない原則です。 しかしこれは オブジェクト指向設計の核心だと Uncle Bob は述べています。 この原則は、次の2つのことを表現しています。
• 拡張に対して開いている(Open): 仕様要求が変更されても、モジュールに新たな振る舞いを追加することでその変更に対処できる • 修正に対して閉じている(Closed): モジュールの振る舞いを拡張しても、そのソー スコードやバイナリコードは影響を受けない
やはり分かりにくいですね。 一言で表現すると、「変わらない部分」と「変わりやすい部分」を分離しようということです。 つまり変わりやすい部分は抽象的に扱い、変わらない部分からのインターフェイスを統一しておけば、変更しなければいけないコードを局所化できるということです。
- 単一責任の原則やインターフェース分離の原則を適用し、モジュールを分割していると「不必要な繰り返し」の臭いがしてくる
- そこで利用するのが開放閉鎖の原則。
- インターフェース分離の原則に従い、インターフェースを必要最小限まで分離した際、新たにインターフェースが増えた時にそのインターフェースを利用する側にも変更を加えなくてはいけなくなるという状態に陥るが、
- その時にStrategyパターンのようにラッパーとなるインターフェースを作成して呼び出し元はそれに依存するようにすることで、呼び出し元には変更を加えなくてもよくなる。
L: リスコフの置換原則 (Liskov Substitution Principle)
-
リスコフの置換原則は継承を利用した原則だが、Swift(を始めとする最近の言語)ではProtocol-Oriented Programmingが主流で、継承ではなくインターフェースで型を設計する。
-
継承の問題点
- 複数のオブジェクトで暗黙的に同じデータが共有される
- 継承に過剰に縛られ、親クラスが保持するプロパティに合わせたり、不変条件を壊さないための考慮が必要
- オーバーライドしたメソッドの引数が親クラスになるため、型の関係性を失う
「継承よりコンポジション」という金言もあります。継承を使いたくなったときには、まずは別の手段で開放閉鎖を実現できないか考えてみてください。
GUIアーキテクチャ
UI と Modelとを分離すること(Presentation Domain Separation) にフォーカスしたアーキテクチャ
ただ、PDSによってきれいに関心を分離できたように見えるのは、あくまで View からの視点でしかないことに注意してください。 というのも、システム全体を俯瞰的に見ると「UI にもシステム本来の関心にも該当しない処理」が存在するからです。 たとえば「サーバ APIからのデータ取得を試み、そこで発生したネットワークエラーをハンドリングする」「データをストレージに永続化する」といったデータ入出力にまつわる煩雑な処理はシステム本来の関心とは言いがたいでしょう。 GUIアーキテクチャの文脈でのModelの正体は、実際には「UIに関係しない処理すべて」と形容すべき、ざっくりした存在です。 Modelをもっと具体的な何かだと思い込んでしまうのは典型的な過ちです。 UI が関わる世界より先のことは、GUIアーキテクチャは何も示していないのです。
MVC
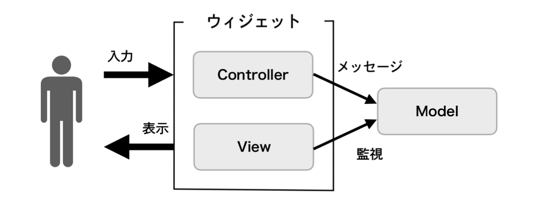
-
GUIアーキテクチャの始祖
-
ドメインロジックを閉じ込めたModelを分離することが目的だった
-
ウィジェットとはButtonなどのUIパーツのこと
-
Controller
- ユーザーの入力を受け取ってModelにコマンドを送る
-
Model
- Stateやロジックを持ち、コマンドによって処理を実行、自身を更新する
-
View
- Modelの状態を監視し、変更があったらそれを反映する
MVP
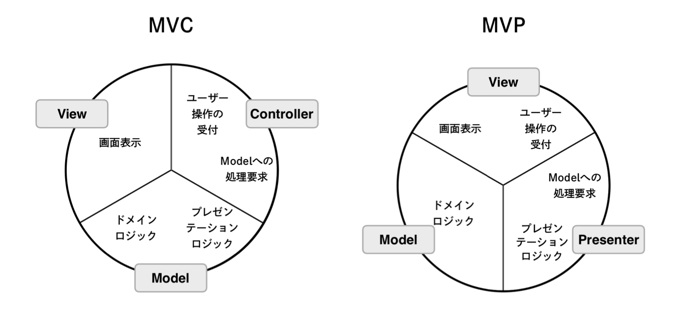
- MVCの問題点として表示に関するロジック(Presentational Logic)や表示に関するStateもModelが持つ必要があった
- そこで上図のようにMVCを60度回転して、役割を変更したのがMVP
MVVM
-
データバインディングを導入
- 双方向と単方向がある
-
MVCやMVPまでは自身でViewを更新するロジックを実装する必要があったが、MVVMではコードを書かなくても自動でデータバインディングが行われるようになった
-
データバインディングはメモリを消費するため、富豪的なアーキテクチャと言われていた
Flux
- ドメインとViewを分離するという前提の上で、一方向のデータフローを明確に示したアーキテクチャ
Redux
-
Fluxの一方向のデータフローに純粋関数による副作用の排除を入れ込んだ
-
Flux アーキテクチャの情報の伝播を1方向に制限する特徴を踏襲し、いつどのように 更新が起きるかを明瞭にする
-
Elm アーキテクチャの純粋関数による副作用の排除や、イミュータブルな状態表現の制約を踏襲し、厳格で整合性のとれた状態管理を実現する
システムアーキテクチャ
UIだけでなくアプリケーション全体、つまりModelの内部表現にまで踏み込んだアーキテクチャ
Layered Architecture
- View以外のコードをレイヤーに単純に分離したもの
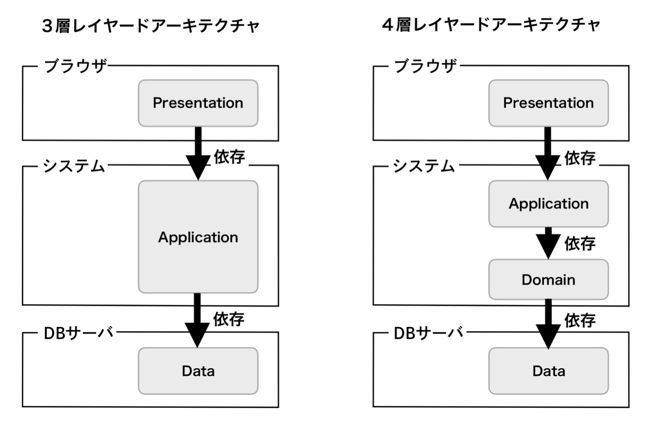
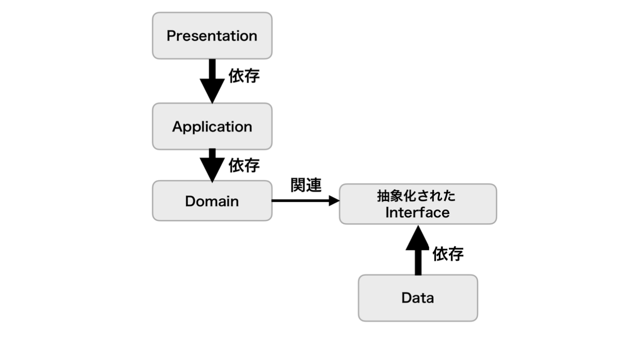
- 単純にレイヤー分けしただけだと、DomainがData層に依存してしまい、永続化の手段を切り替えることができなくなる
- そのため、依存性逆転の原則を適用してDomain側で用意したInterfaceにData層が依存するようになった
Hexagonal Architecture
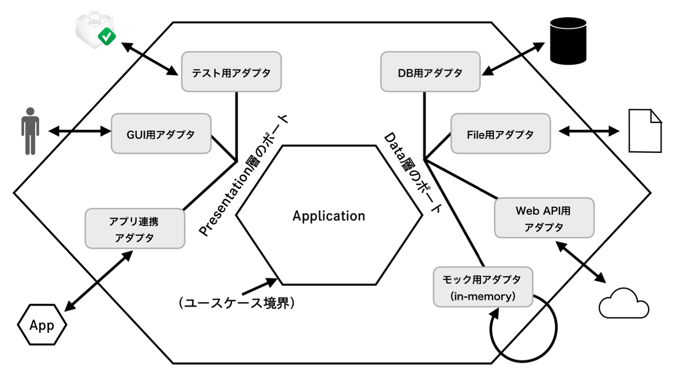
- Layered ArchitectureにData層だけでなくPresentation層も入れ込み、上下という関係ではなく「Data層とPresentation層は外部と接続するレイヤー」と捉えて六花形で表したArchitecture
Onion Architecture
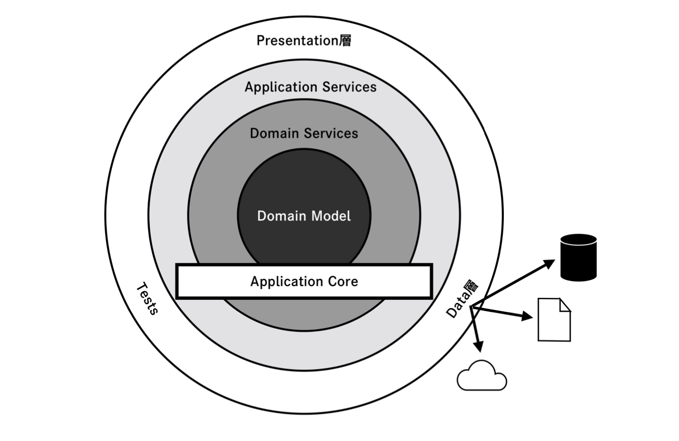
-
Hexagonal Architectureのアプリケーションの内部を更に複数の層に分離して表現したArchitecture
-
依存の方向は外側から内側
- 内側のレイヤーはインターフェイスを定義し、外側のレイヤーはそれを実装する
-
Application Core はインフラストラクチャ(Data 層)抜きでコンパイル・実行できる
Clean Architecture
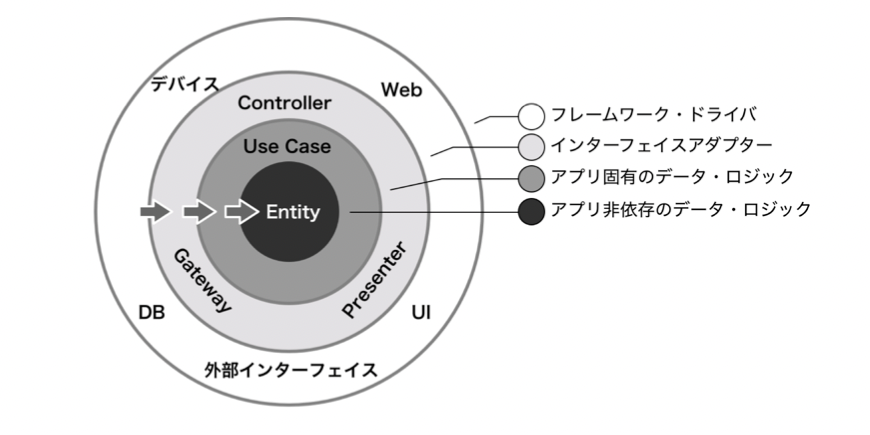
- 中身はOnion Architectureと同じ
- 当時乱立していたシステムアーキテクチャを統一し、iOSやWebappやAPIなどどのようなシステムでも利用できるアーキテクチャという意味でCleanと名付けた
同じシステムアーキテクチャであるレイヤードアーキテクチャと比較すると、レイヤードアーキテクチャではデータベースなどの永続化を担う層がドメインを担当する層の下にいて、ドメインが永続化層に依存しています。 一方、Clean Architectureはデータベースを円の外側に置き、依存の方向が逆転しています。 さらにデータベースと Use Caseの間には変換層を挟んでいて、切替が容易なしくみをもっている点が異なります
Use Case と Entity の間は単純なコマンドとクエリにすべきです。
アプリケーションに依存しないビジネスロジックである Entityは、単純なコマンドとクエリだけを持っていれば成立するはずですし、Entity が特定の Use Caseからだけ参照されることを期待する作りにするべきではありません。
Frontend特有のアーキテクチャ
Application Coordinator
-
Frontendの場合、UIの描画、Modelの内部の処理だけではなく、複数画面間の遷移が存在する。
-
特にスマホアプリの場合はHome画面からの起動、通知からの起動、Deep Linkによる起動など起動導線が複数存在するため、View Controllerの画面遷移ロジックがどんどんFatになり、可読性が低下していく。
-
画面の遷移導線とUIの処理は「変更の理由」が異なる事が多いため、単一責任の原則にも反する。
-
画面遷移のロジックを各View Controllerに書くのではなく、別のCoordinatorとして切り出し、そこに起動経路による分岐ロジックなどをまとめることで、画面遷移のロジックを分離する。
-
これにより、View Controllerの肥大化を防ぎ、画面遷移のロジックをユニットテストしやすくすることができる。
Router
-
モチベーションはApplication Coordinatorと同じ。
-
Coordinatorは起動経路のロジックをまとめる大きめのClassなのでプロジェクトの途中から導入するには重い。
-
Routerは単にView Controllerに存在していた画面遷移のロジックを個別に切り出していくイメージ。
-
VIPERパターンの一部として語られる事が多いが、Routerは単体でも活用可能。
その他の概念
3種のポリモーフィズム
- Ad hoc polymorphism|アドホック多相
- Parametric polymorphism|パラメータ多相
- Subtyping|部分型付け
https://qiita.com/shtnkgm/items/fcc1a1a75895a31df4a9
フロー同期とオブザーバー同期
- オブザーバー同期
- Modelの変更通知をObserverパターンで受け取り、Viewが自分自身を更新
- フロー同期
- Presenterが処理の最中になんらかのタイミングでViewのインスタンスを直接更新
純粋関数と副作用の定義
純粋関数とは、関数の評価において副作用を発生させない点が最大の特性です。 プログラミングの関数における副作用とは、関数に入力されていない要素が出力とは関係ない箇所で 変化することです。 純粋関数の特性を次に列挙します。
• 与えられた要素や関数外の要素を変化させず、戻り値以外の出力を行わない(副作用の排除)
• 取り扱うすべての要素が引数として宣言されている(引数以外の要素を参照しない)
• 入力に対して出力が常に一意である(同じ入力には常に同じ出力を返す)